ClickHouse Analitik işler için tasarlanmış, birinci önceliği hız olan bir OLAP bir DBMS (Database Management System) dir. Analitik sorgularda normal RDBMS veritabanlarına göre kat be kat hızlıdır, Analitik sorgularda hızlı olması için tasarlanmıştır, bunu ise mimari özelliğine borçludur en temel özelliği tabloların column based mimaride olmasıdır. Başlıca öne çıkan özellikleri aşağıdaki gibidir;
- Parallel işlem yapabilme kapasitesi
- Bir çok sunucu üzerinde dağıtık mimaride çalışabilmesi
- Bildiğimiz SQL standardını desteklemesi
OLAP senaryolarında RDBMS yapılara göre 100 kat daha hızlı çalışabilmektedir.
ClickHouse gelişimi
OLAP için tasarlanmış bir veritabanı olduğunu söyledik ve analtik sorgularda çok hızlı olduğuna değindik, bu hızı ise büyük ölçüde Tablola yapısının column based olarak tutması ile ilgili olduğunu söylersek yanlış bir şey söylemiş olmayız fakat biraz daha anlaşılır hale getirmeye çalışalım, column based olunca nasıl oluyorda analitik query ler hızlanıyor; Sebebi ise analitik query ler belli kolonlar üzerinde yapılan hesaplama (sum, avg, vb.) ve sıralama işlemlerine dayanmaktadır bu işlemler ise sadece o kolonlara hızlı bir şekilde ulaşabiliyor ve bu kolonların parçaları üzerinde parallel işlem yapabiliyorsak oldukça hızlanacak demektir, temel olarak hızının kaynağı bu yaklaşımdan gelmektedir. Sadece belli kolonların parçalarını tutmamız işlemler sırasında hem I/O kazancı hem CPU cycle kazancı sağlayacak aynı zamanda sıkıştıma konusunda da oldukça etkili yöntemler geliştirlmesine imkan tanıyacaktır.
Burada dikkat edilmesi gereken bazı noktalar bulunmaktadır, klasik RDBMS yaklaşımı ile geliştirlen OLAP yapılardan farklı bir yaklaşım ile tasarım yapmalıyız istediğimiz performansı alabilmek için küçük küçük az kolonlu bir çok tablo yaklaşımı ve bir çok join işlemleri gibi işlemlerden ClickHouse DBMS de olabildiğince uzak durmaya çalışmalıyız, ne demek istediğimi mimariyi incelediğimizde daha net anlıyor olacağız.
ClickHose kendi içerisinde bir çok analitik fonksiyon barındırmaktadır SQL Standardının desteklemesine rağmen bu fonksiyonlar ile standart SQL den farklılaşmaktadır.
ClickHouse Data Types
- Integer types: signed and unsigned integers (
UInt8,UInt16,UInt32,UInt64,UInt128,UInt256,Int8,Int16,Int32,Int64,Int128,Int256) - Floating-point numbers: floats(
Float32andFloat64) andDecimalvalues - Boolean: ClickHouse has a
Booleantype - Strings:
StringandFixedString - Dates: use
DateandDate32for days, andDateTimeandDateTime64for instances in time - JSON: the
JSONobject stores a JSON document in a single column - UUID: a performant option for storing
UUIDvalues - Low cardinality types: use an
Enumwhen you have a handful of unique values, or useLowCardinalitywhen you have up to 10,000 unique values of a column - Arrays: any column can be defined as an
Arrayof values - Maps: use
Mapfor storing key/value pairs - Aggregation function types: use
SimpleAggregateFunctionandAggregateFunctionfor storing the intermediate status of aggregate function results - Nested data structures: A
Nesteddata structure is like a table inside a cell - Tuples: A
Tupleof elements, each having an individual type. - Nullable:
Nullableallows you to store a value asNULLwhen a value is “missing” (instead of the column settings its default value for the data type) - IP addresses: use
IPv4andIPv6to efficiently store IP addresses - Geo types: for geographical data, including
Point,Ring,PolygonandMultiPolygon - Special data types: including
Expression,Set,NothingandInterval
ClickHouse DBMS te bildiğimiz tablo yapılarından farklı olarak, data saklama şekli ile data türüne göre ayrıca sorgu şekillerine göre farklı Table Engine yapıları tanımlanabilmektedir. En yaygın kullanılan TableEngine yapısı MergeTree Türü Tablo Engine Ailesidir. Nasıl tanımlanır; Tablo Create ederken bu belirtilir.
CREATE TABLE test_db.table1
(
id UInt64,
column1 String
)
ENGINE = MergeTree
ORDER BY idClikHouse DBMS te alıştığımız yapılardan farklı olarak, Primary Key ve Primary Index Kavramları burada oldukça farklıdır. Primary KEY tanımlarken tablo oluşturuken yukarıda olduğu gibi bir ORDER BY ifadesi ile PK tanımı yapılabilmektedir.
- PK tanımlanan alanların Unique olması gerekmez
- En çok sorgulanan kolonlar PK olarak seçilmelidir
- PK seçimi Performans açısından oldukça önemlidir.
MergeTree Engine Ailesi Tablolar Ve Data Store Şekli
ClickHouse MergeTree Tablolarda Performans alabilmek için Bulk Insert ler ile çalışmayı tavsiye eder, sebebi ise her bir bulk insert bir PART oluşturur, Her bir PART ise içerisinde o PART ın datala file ları içeren Klasörlerdir. Her bir PART yüzler, binler hatta milyonlarca satır data içerebilirler.
Create table my_table
(
col1 FixedString(1),
col2 UInt32,
col3 String
)
ENGINE=MergeTree
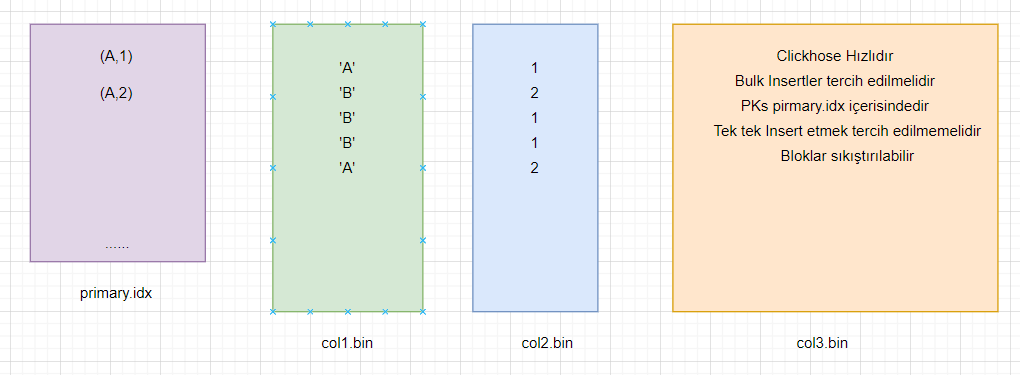
ORDER BY (col1, col2)insert into my_table (col1,col2,col3) values
('B',1,'Clickhose Hızlıdır'),
('A',1,'Bloklar sıkıştırılabilir'),
('B',2,'Bulk Insertler tercih edilmelidir'),
('A',2,'Tek tek Insert etmek tercih edilmemelidir'),
('B',2,'PKs pirmary.idx içerisindedir')Her kolon ve PK Index immutable file içerisinde datalarıya tutulur,
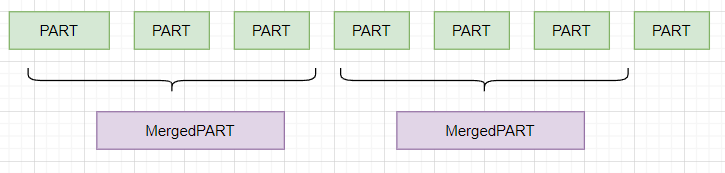
Her bulk insert bir PART oluşturur. Zamanla arkaplanda PART lar birleşit ve MergedPART lara dönüşür,
bu sırada kullanılmayan PART lar delete edilir,
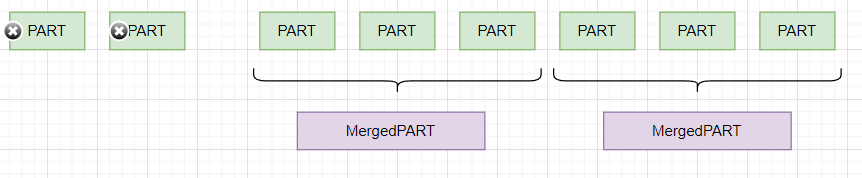
zaman içinde MergedPART larda birleşmeye devam ederek yeni MergedPART lara dönüşür.
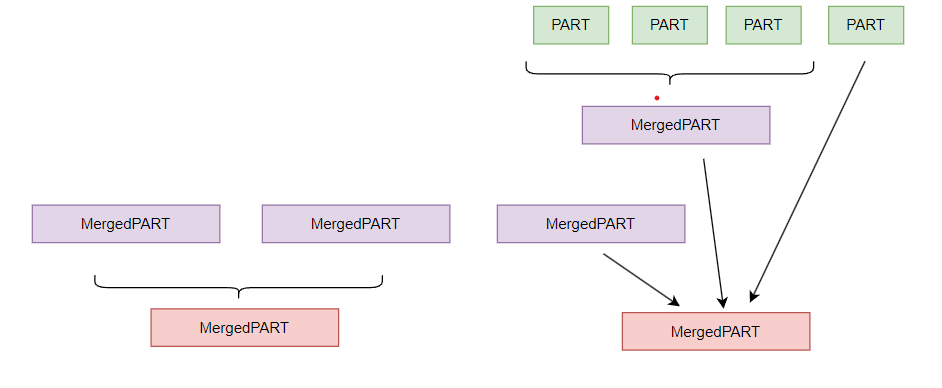
MergePART lar max boytunu belirleyen parametre
max_bytes_to_merge_at_max_space_in_pool dir ve default değeri 150 GB tır.
MergeTree Tablo dataları temelde basit olarak bu şekilde dizayn edilmektedir peki Primary KEY Indexleri nasıl tutulur; ClickHouse indexleme yapısı bildiğimiz veritabanı index yaklaşımından oldukça farklıdır, ve Performasn açısından PKs seçimi oldukça kritiktir. Bu seçimi doğru yapabilmek için index yapsının ve veri dopalama şeklinin net bir şekilde anlaşılması gerekmektedir.
ClickHouse da tablo datası GRANUL adı verilen gruplara ayırmaktadır,
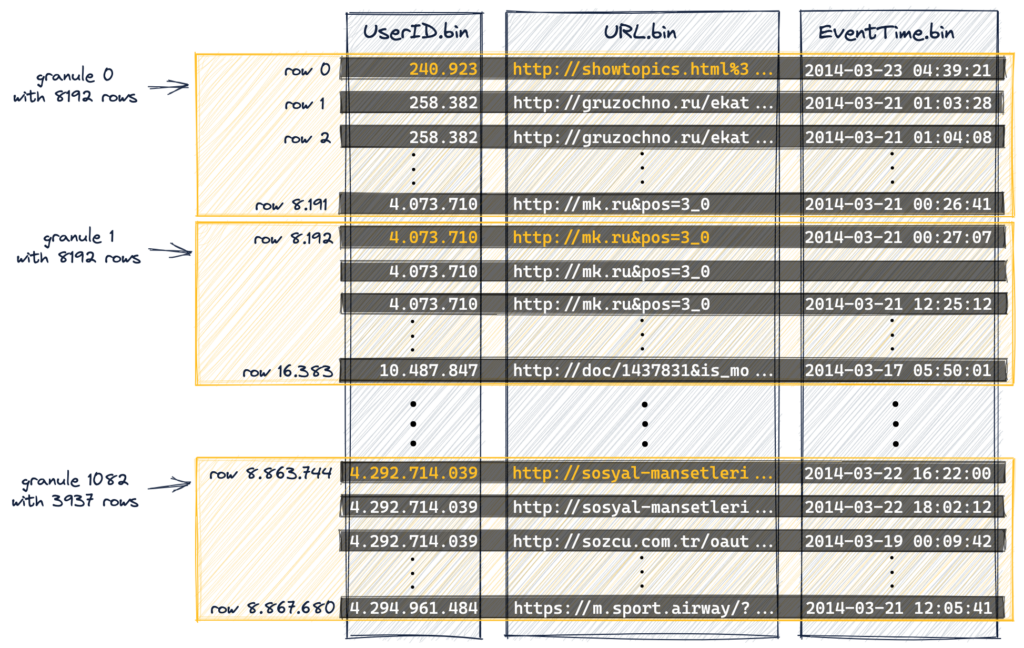
Default durumda her granül 8192 row kayıttan oluşmaktadır. Bir tablonun ne kadar GRANUL e ayrıldığını bulmak için;
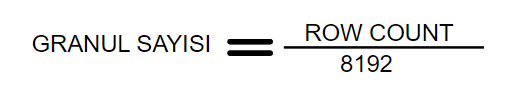
Burada granül yapısı ile doğal bir partition yapısı oluşmaktadır. Primary KEY indexleri , diğer veritabanlarındaki gibi her satırın değerini kaydetmek yerine , herbir GRANÜL ün ilk değerini depolar ve bunlarıda memory üzerinde tutar. Bu sayede milyonlarca satırı olan bir tablonun PK Indexleri binler ile ifade edilir. Bu Clickhouse OLAP DBMS i bulk işlemlerde hızlı yapan unsurdur.
ClickHouse satırları okurken bölünemez en küçük yapısına GRANUL denir.
Select * from clikhouse_table where col1='B' and Col2=2
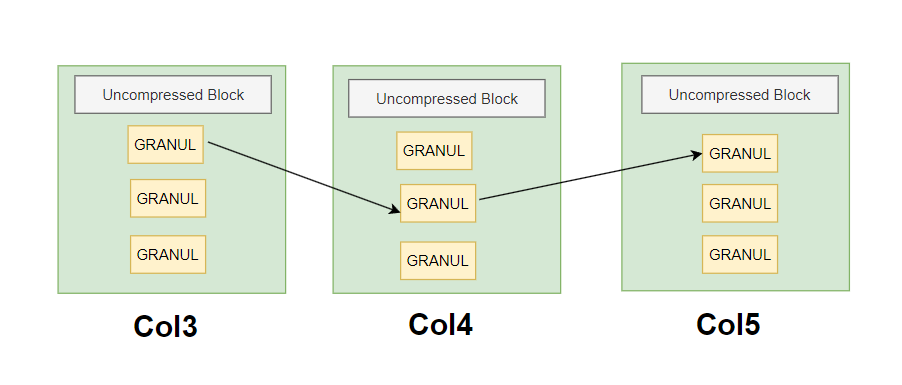
Bir sorgudaki her bir granül şeridi eğer donanım kaynakları imkan veriyorsa bir thread prosesi oluşturabilir, bir prosess bitince yeni bir granül şeridini devralır, hızlı olan prosess yavaş olanın yerini alabilir.
Buraya kadar İncelediğimiz Kavramların tanımlarına bir göz atarsak;
GRANUL –> Sıkıştırılmamış blokların içerisindeki satırların logic dökümüdür , bir clikhose sorgusunda parçalanamayan en küçük veri yapısıdır ve varsayılan olarak 8192 row içerir.
PRIMARY INDEX : Primary Key olarak tanımlanan kolonlar için herbir GRANUL parçasının ilk kaydını içeren index biçimidir. Memory üzerinde tutulmaktadır, memory üzerine sığmaz ise ClickHouse Crash olur ve açılamaz.
PART : Bir tablonun kolonlarının ve inde datasının bir kısmını turan dosya klasörüdür.





Bir yanıt yazın