
Elasticsearch Mimarisi: Ölçeklenebilir ve Güçlü Bir Arama Motoru
Elasticsearch, büyük miktarda veriyi hızlı ve etkili bir şekilde arama ve analiz etme amacıyla tasarlanmış, açık kaynak kodlu bir arama motorudur. Temelde bir NoSQL veri tabanı olan Elasticsearch, özellikle yüksek hacimli veri ve karmaşık sorgularla başa çıkmak için geliştirilen bir mimariyi kullanır. Bu yazıda Elasticsearch’ün temel bileşenlerini ve mimari yapısını inceleyeceğiz.
1. Temel Bileşenler
Elasticsearch, esneklik ve ölçeklenebilirlik sağlamak için belirli bileşenler üzerine kuruludur. Bu bileşenler, veriyi düzenli bir şekilde dağıtmak ve arama performansını optimize etmek için birlikte çalışır.
Cluster
Elasticsearch, birden fazla node’dan (düğüm) oluşan bir cluster yapısına sahiptir. Cluster, tüm veriyi saklayan ve sorguları işleyen birden fazla node’un birlikte çalıştığı bir yapıdır. Cluster, veri fazlalığı ve hata toleransı için oldukça önemlidir.
•Cluster Name: Cluster’ın tüm node’ları aynı isimdeki bir cluster’da toplanır. Varsayılan olarak “elasticsearch” ismine sahiptir, ancak üretim ortamında benzersiz bir isim kullanılması önerilir.
Node (Düğüm)
Node, Elasticsearch’te veri depolayan ve arama işlemlerini yürüten en temel bileşendir. Her bir node, bir Elasticsearch sürecidir ve farklı görevleri üstlenebilir. Cluster’daki her node, diğer node’larla birlikte çalışarak veriyi işler.
•Node Türleri:
•Master Node: Cluster yönetim görevlerini (örneğin, shard atamaları, indeksleme ve node’ları izleme) üstlenir.
•Data Node: Veriyi saklayan ve CRUD işlemlerini gerçekleştiren nodelardır. Yoğun veri işleme ve arama yükünü taşır.
•Ingest Node: Veri girerken ön işlem görevlerini yerine getirir.
•Coordinating Node: Sorguları alıp diğer node’lara dağıtır ve sonuçları toplar.
Index (İndeks)
Elasticsearch’te veri, index adı verilen mantıksal yapılarda saklanır. Bir indeks, belirli bir veri setini veya belge grubunu içerir. SQL dünyasında bir tabloya benzeyen indeksler, Elasticsearch için temel depolama birimleridir.
Document (Belge)
Veriler, document (belge) adı verilen JSON formatında depolanır. Bir belge, Elasticsearch indeksinde saklanan bir veri birimidir. Örneğin, bir müşteri kaydı veya ürün bilgisi birer belgedir.
Shard ve Replica (Parça ve Kopya)
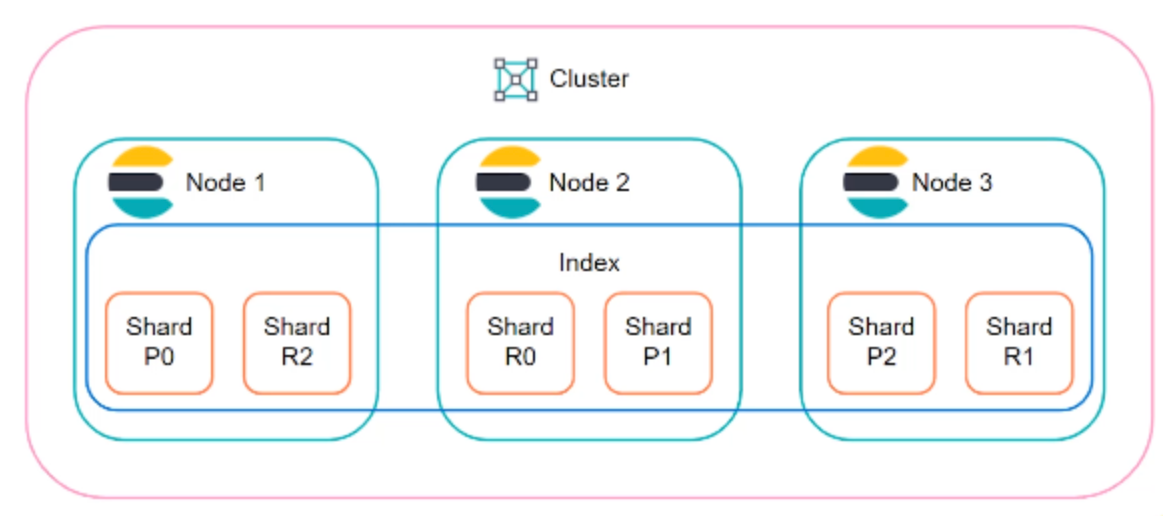
Her indeks, shard adı verilen parçalara bölünür. Bu, veriyi daha küçük parçalara ayırarak paralel işlemeyi sağlar. Elasticsearch ayrıca veri güvenliği ve erişilebilirliği sağlamak için her shard’ın replica adı verilen kopyalarını oluşturur.
•Primary Shard: Verinin orijinal kopyası.
•Replica Shard: Verinin yedek kopyası, yüksek erişilebilirlik için kullanılır.
2. Elasticsearch Dağıtık Mimarisi

Elasticsearch’in dağıtık mimarisi, veriyi parçalara ayırıp dağıtarak hem veriye hızlı erişim sağlar hem de hatalara karşı dayanıklılığı artırır. Bu sistem, büyük veri kümelerini etkin bir şekilde işlemenin yanı sıra esneklik ve ölçeklenebilirlik açısından önemli avantajlar sunar.
Shard ve Replica Yönetimi
•Shard’ların Dağıtımı: Bir indeksin shard’ları cluster’daki farklı data node’lara dağıtılır. Bu sayede verinin farklı nodelara dağılmasıyla veri işleme yükü dengelenir.
•Replica Yönetimi: Replica shard’ları, primary shard’ın kopyası olarak başka bir node üzerinde saklanır. Böylece bir node devre dışı kalsa bile veriye erişim devam eder.
Sorgu Yönlendirme ve Koordinasyon
Koordinasyon node’u, bir sorgu geldiğinde bu sorguyu ilgili node’lara yönlendirir. Sorgu tamamlandığında, tüm sonuçları toplar ve istemciye yanıt olarak döner. Bu yapı, sorguların paralel olarak yürütülmesini ve sonuçların hızla döndürülmesini sağlar.
3. Elasticsearch Veri Akışı ve Sorgulama Süreci
Veri akışı, Elasticsearch’te şu şekilde gerçekleşir:
1. İndeksleme Süreci: Veri girildiğinde JSON formatında belgeler olarak saklanır ve indekslenir. Bu indeksleme, verinin hızlıca bulunabilmesi için önemlidir.
2. Arama Süreci: Kullanıcı sorguları koordinasyon node’u tarafından karşılanır ve arama işlemi ilgili data node’lara iletilir.
3. Sorgu Sonuçlarının Birleştirilmesi: Her bir node sorgu sonuçlarını geri döndürür ve sonuçlar koordinasyon node’u tarafından birleştirilip istemciye iletilir.
Bu süreç, Elasticsearch’ün hızlı sorgu yeteneğini ortaya koyan ve performansını optimize eden bir veri akışıdır.
4. Elasticsearch Yüksek Erişilebilirlik ve Ölçeklenebilirlik
Elasticsearch, cluster mimarisi sayesinde yüksek erişilebilirlik ve ölçeklenebilirlik sunar. Veri ve işlem yükü, cluster içinde farklı nodelara dağıtılır, bu da aşağıdaki avantajları sağlar:
•Yüksek Erişilebilirlik: Replica shard’lar sayesinde bir node devre dışı kalsa bile veri kaybı yaşanmaz ve sistemin kullanılabilirliği korunur.
•Yatay Ölçeklenebilirlik: Cluster’a yeni node eklenerek veri depolama ve işlem kapasitesi artırılabilir. Bu özellik, özellikle büyük veri setleriyle çalışan uygulamalar için kritik öneme sahiptir.





Bir yanıt yazın